Storytelling from an Image Stream Using Scene Graphs论文详解
本文介绍了复旦大学研究团队在AAAI 2020上录用的一篇关于多模态文本生成工作:Storytelling from an Image Stream Using Scene Graphs,主要从作者信息、问题背景、解决方案、实验、结论等方面进行解读。
Paper Reading的slides与talk video可以在刘家瑛老师团队的主页上找到。
作者简介
Ruize Wang (Master, Fudan University)
复旦大学的master,个人信息不多。
Zhongyu Wei (Associate Professor, Fudan University)
魏忠钰,复旦大学的Associate Professor,主要研究兴趣为NLP/generation cross vision and language。教育背景:港中文PHD,University of Texas博士后。
Piji Li (Senior Researcher, Tencent AI Lab)
李丕绩,腾讯AI实验室的Senior Researcher,主要研究兴趣为NLP/CV/深度学习。教育背景:港中文PHD,山东大学bachelor&master。
Qi Zhang (Professor, Fudan University)
张奇,复旦大学的Professor,主要研究兴趣为NLP/information retrieval。教育背景:复旦大学PHD,山东大学bachelor。
Xuanjing Huang (Professor, Fudan University)
黄萱菁,复旦大学的Professor,主要研究兴趣为NLP/information retrieval。教育背景:复旦大学PHD&bachelor。
问题背景
For most people, showing them images and ask them to compose a reasonable story about the images is not a difficult task.
对大多数人而言,向他们展示图像并要求他们撰写有关图像的故事并不是一件困难的事。(回忆我们小学的看图写话任务)
It is still nontrivial for the machine to summarize the meanings from images and generate a narrative story.
但是对于机器来说,目前并没有nontrivial的方法从图像中总结出含义并产生叙事故事。
Existing methods for visual storytelling employ encoder-decoder structure to translate images to sentences directly.
现有的用于视觉叙事的方法采用编码器-解码器结构来将图像直接翻译成句子。
一个visual storytelling的例子:
现有的解决方案:
- seq2seq (Huang et al. 2016): Encodes an image sequence by running an RNN, and decodes sentences with a RNN decoder.
- BARNN (Liu et al. 2017): With attention on semmatic relation to enhance the textual coherence in story generation.
- h-attn-rank (Yu, Bansal, and Berg 2017): A hierarchically-attentive RNN based model consisting of three RNN stages, i.e., encoding photo stage, photo selection stage and generation stage.
- HPSR (Wang et al. 2019): HPSR is a model includes the hierarchical photo-scene encoder, decoder, and reconstructor.
- AREL (Wang et al. 2018b): Based on reinforcement learning. It takes a CNN-RNN architecture as the policy model for story generation.
- HSRL (Huang et al. 2019): A hierarchically structured reinforcement learning approach, which propose to generate a local semantic concept for each image in the sequence and generate a sentence for each image using a semantic compositional network.
算法
大致思路
When we humans telling stories for an image sequence, we will recognize the objects in each image, reason about their visual relationships, and then abstract the content into a scene. Next, we will observe the images in order and reason the relationship among images.
当人类为一个图像序列讲故事时,将识别每个图像中的对象,推理它们的视觉关系,然后将内容抽象到场景中。接下来,我们将按顺序观察图像并推理图像之间的关系。
We presents a novel graph-based architecture named SGVST for visual storytelling.
基于这样的想法,本文提出了一种新颖的基于图形的架构,名为SGVST,用于视觉叙事。
详细模型
问题
Input: an image stream $I = \{I_1,I_2,\cdots,I_n\}$
Output: a story $y=\{y_1,y_2,\cdots,y_n\}$, where $n$ is the number of images in the image stream, and sentence $y_i=\{w_1,w_2,\cdots,w_T\}$.
输入为一组图像($n$ 张),输出为一个故事,由$n$个子句组成,每句对应一张图片,是词汇表vocabulary上单词的序列。
算法步骤
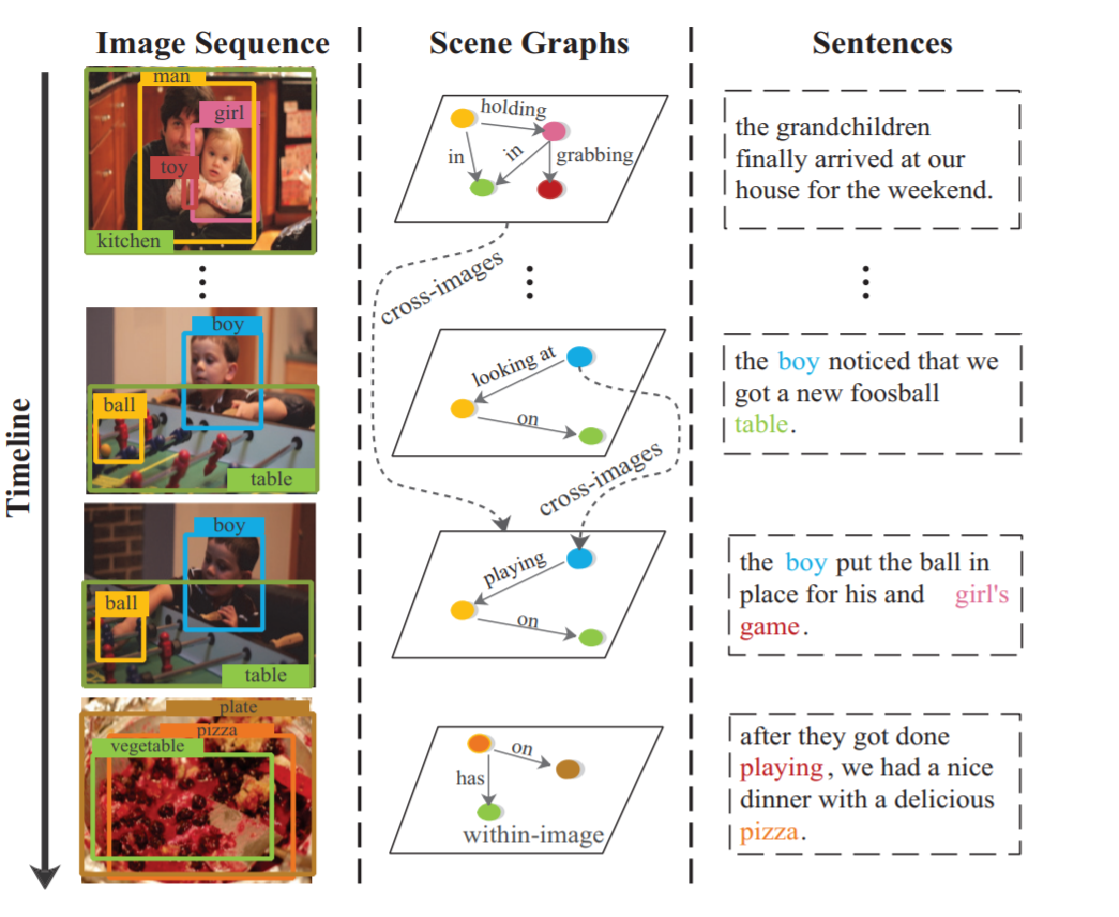
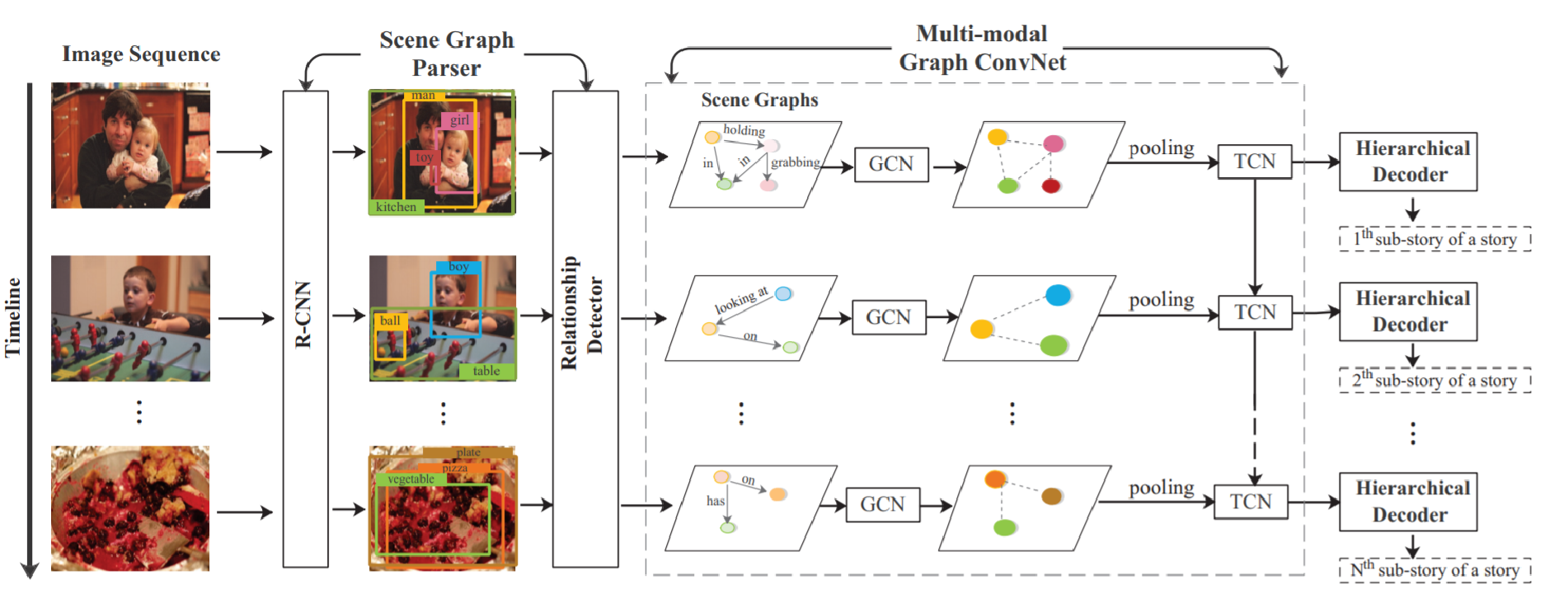
Use a scene graph parser to translates each image into a scene graph, and then models the relationship on within-image level and cross-images level.
What is “scene graph”?
Vertexes represent different regions and directed edges denote relationships between them, using tuples $\langle subject-predicate-object\rangle$.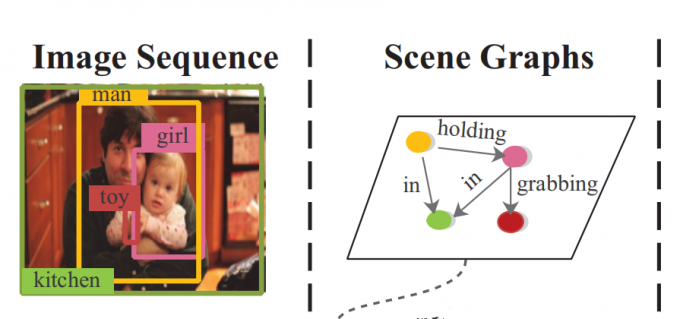
A pre-trained scene graph parser gives scene graphs $G=\{ G_1,\cdots,G_n \}$.
where $G_i = \langle V_i, E_i \rangle $.Each graph includes a set of detected objects, and vertex (object) represents each region and the edge denotes the visual relationship between them.
场景图就是对图片的抽象,用“图”结构来表示,定点为图像中的物体,边为物体之间的关系。
如:$\langle$小女孩-抱着-玩具$\rangle$。
因此分为两个阶段:1. 物体检测 2. 关系检测
Object Detector: Use pre-trained Faster-RCNN
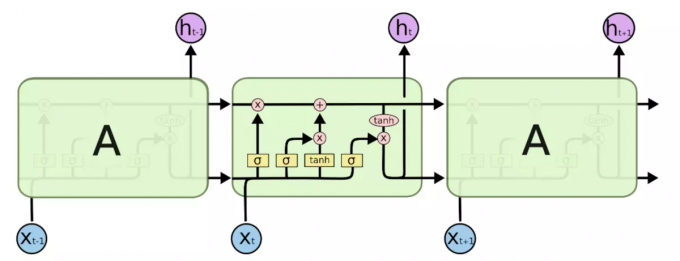
Relationship Detector: Use the LSTM-based model (Zellers et al. 2018), train on Visual Genome dataset
LSTM(Long Short-Term Memory)是一种时间循环神经网络(RNN),能够学习长的依赖关系。所有循环神经网络都具有神经网络的重复模块链的形式。 在标准的RNN中,该重复模块将具有非常简单的结构。
一个大概的示意图如下:
Processing the scene graphs to enrich region representations. Use Graph Convolution Network (GCN) which passes the information along graph edges.
Given an input graph with vectors of each node and edge, it computes new vectors for each node and edge. Each graph convolution layer propagates information along edges of the graph.
把生成的场景图扔进GCN,进行进一步的增强。GCN是图神经网络,可以使用图的特征去对图数据进行节点分类(node classification)、图分类(graph classification)、边预测(link prediction)。这一步是继续增强已有的场景图中的关系。
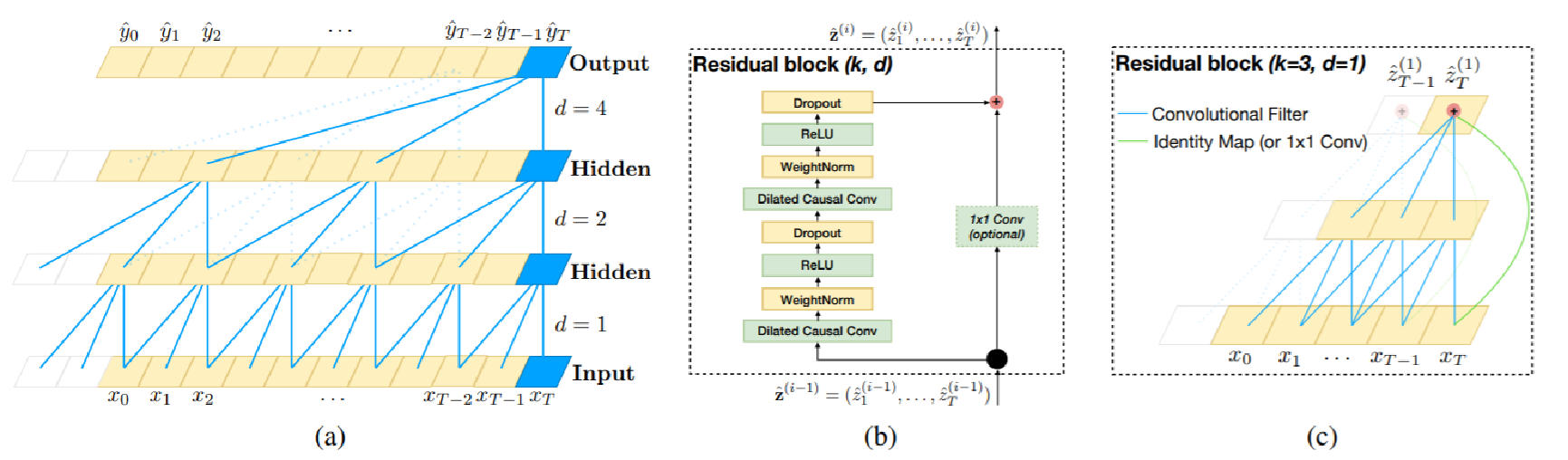
Use Temporal Convolution Network (TCN) to process the region representations along the temporal dimension, which models relationships on cross-images level.
TCN是关注时序关系的网络。时序问题的建模大家一般习惯性的采用循环神经网络(RNN)来建模,这是因为RNN天生的循环自回归的结构是对时间序列的很好的表示。传统的卷积神经网络一般认为不太适合时序问题的建模,这主要由于其卷积核大小的限制,不能很好的抓取长时的依赖信息。
TCN的主要思路:Causal Convolution + Dilated Convolution + Residual Connections
单纯的因果卷积还是存在传统卷积神经网络的问题,即对时间的建模长度受限于卷积核大小的,如果要想抓去更长的依赖关系,就需要线性的堆叠很多的层。为了解决这个问题,又加入了膨胀卷积。
残差链接被证明是训练深层网络的有效方法,它使得网络可以以跨层的方式传递信息。本文构建了一个残差块来代替一层的卷积。如图所示,一个残差块包含两层的卷积和非线性映射,在每层中还加入了WeightNorm和Dropout来正则化网络。
After 2 and 3, we get the relation-aware representations on both within-image and cross-images levels.
2和3步骤最大的作用就是让我们拿到了既有图像内部层面、又有图像之间层面关系的场景图。
Use a bidirectional-GRU to encode the feature maps obtained from Faster R-CNN as high-level visual features.
GRU对于RNN中的梯度消失有很大帮助。为了克服RNN无法很好处理远距离依赖而提出了LSTM,而GRU则是LSTM的一个变体,当然LSTM还有有很多其他的变体。GRU保持了LSTM的效果同时又使结构更加简单。
Injecting all of the relation-aware representations into a two-layer GRU with attention mechanism.
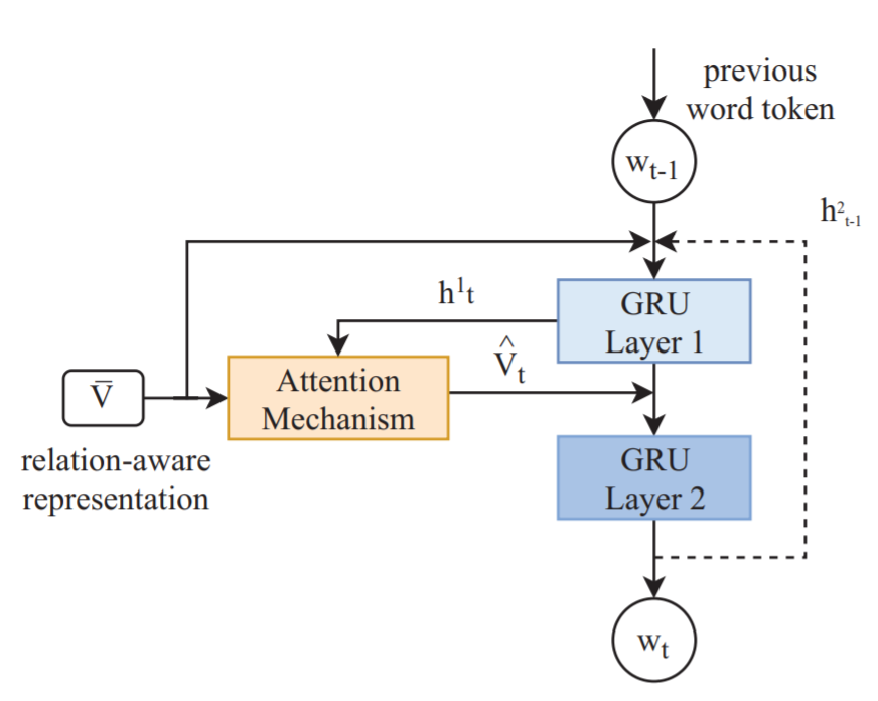
总的结构如下图所示:
训练
In the training stage, we fix the parameters of our pre-trained scene graph parser, and other components of our model are trained and evaluated on VIST dataset for visual storytelling task.
Define cross-entropy (MLE) loss for the training process.
Here $y$ is the ground truth story.
实验
数据集
Visual Storytelling (VIST)
Includes 10,117 Flicker albums with 210,819 images.
40,098 for training, 4,988 for validation and 5,050 for testing, respectively. Each sample (album) contains five images and a story with five sentences.
Huang et al. 2016. Visual storytelling. In NAACL (Microsoft, CMU & JHU)
The first sequential vision-to-language dataset.Visual Genome (VG)
108,077 images annotated with scene graphs, containing 150 object classes and 50 relation classes.
Only used to train the relationship detector in our scene graph parser.
Krishna, R. et al. 2017. Visual genome: Connecting language and vision using crowdsourced dense image annotations. In IJCV (Stanford)
评价指标
Seven automatic evaluation metrics
BLEU (Papineni et al. 2002)
Calculate scores on 1-gram, 2-gram, 3-gram and 4-gram.
ROUGE-L (Lin and Och 2004)
Uses the length of LCS (longest common subsequence)
METEOR (Banerjee and Lavie 2005)
Considers stemming and synonymy matching, along with the standard exact word matching.
CIDEr-D (Vedantam, Lawrence Zitnick, and Parikh 2015)
Also n-gram, but decreases the weight of less informative ones.
Considers stemming and synonymy matching.
Human Evaluation
- Pairwise Comparison
- Human Rating
实验结果
与现有算法的比较
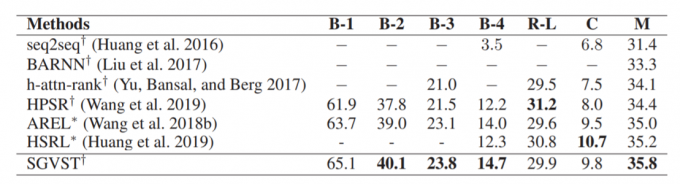
结果显示SGVST模型几乎在所有指标上都优于其他用MLE和RL优化的模型具有更好的性能,SGVST的BLEU-1、BLEU-4和METEOR得分比其他基于MLE优化的最佳方法分别提高了3.2%、2.5%和1.4%,这被认为是在VIST数据集上的显著进步。这直接说明将图像转换为基于图的语义表示(如场景图),有利于图像的表示和高质量的故事生成。
消融实验,和提出模型的5个变种模型进行了比较
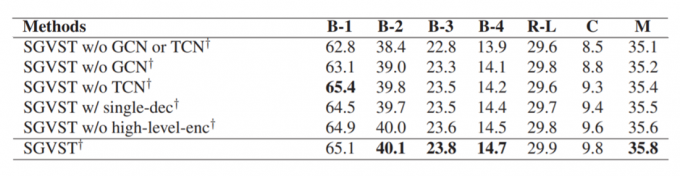
在不使用GCN和TCN的时候,模型性能有一个很大的下降。这说明图网络在该模型中是最为重要的,因为它可以给模型带来了推理视觉关系的能力。
人工评价
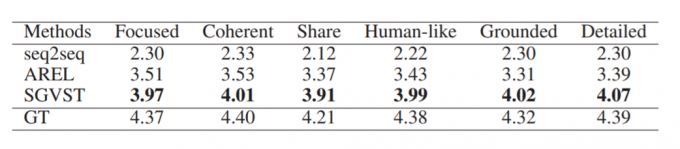
在AMT上的评估人员根据对每个问题的同意程度来评价故事的质量,评分范围为1-5。
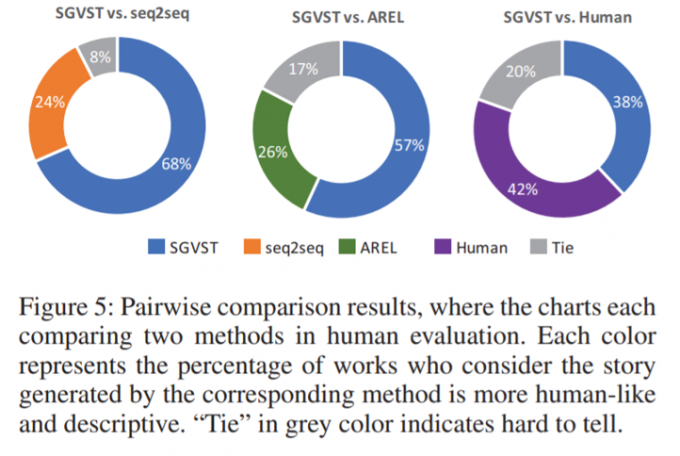
每种颜色代表了相对应模型产生的故事,被评价人员认为更加像人写的、更有表现力所占的比例。灰色的“Tie”代表了无法区分。
总而言之,通过Amazon Mechanical Turk(AMT)进行了两种人工评价。在6个指标上进行的人工评估实验结果。可以看出本文提出的模型和其他模型相比有着巨大的优势,而且和人类相比,也取得了有竞争力的表现。
结论
- Translate images into graph-based semantic representations called the scene graphs.
- Realize enriching fine-grained representations both on the within-image level and the cross-images level.
- Extensive experiments demonstrate that SGVST achieves state-of-the-art, and the stories generated are more informative and fluent.