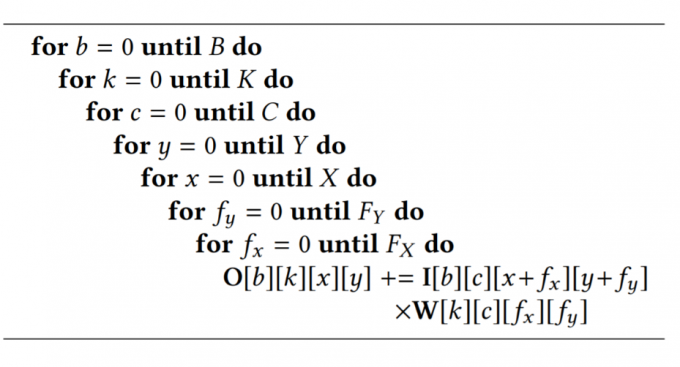本报告是基于论文Interstellar: Using Halide's Scheduling Language to Analyze DNN Accelerators,对不同的dataflow模式对循环加速效果的探究。伴随着深度神经网络(DNN)正在包括自动驾驶、人脸识别、人脸检索和图像识别在内的各领域得到更加广泛地应用,业界对DNN加速器的需求也在不断增加。而DNN对算力的要求增长非常快,远超摩尔定律所预测的CPU集成度与性能的增长速度。因此,对DNN加速器的研究是非常重要的。
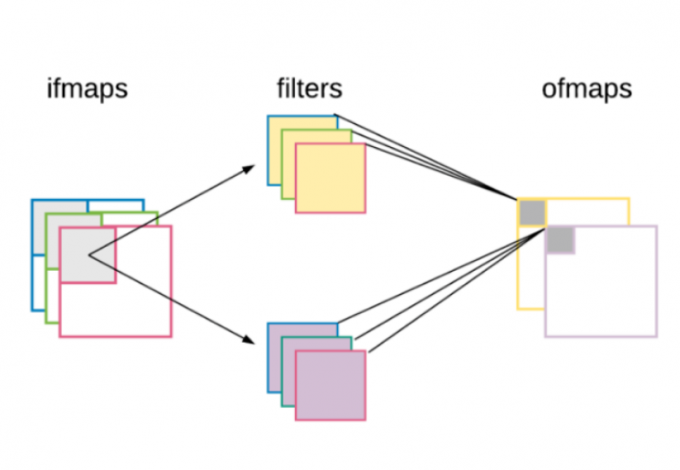
目前上层软件主要根据CNN等卷积神经网络相关算法进行调度。CNN是由多个2D的input features maps(ifmaps)产生多个输出的output features maps(ofmaps),在每一对ifmaps和ofmaps之间对应一对2D的filters,同时由于ifmaps和ofmaps是3D的,每一对均对应一对filters,所以filters实际上存在4D的张量结构,即除了每一个2D的filters之外,可以认为所有的ifmaps的一组和相同数量的filters产生一个ofmaps,而每一个ofmaps都对应一组filters。
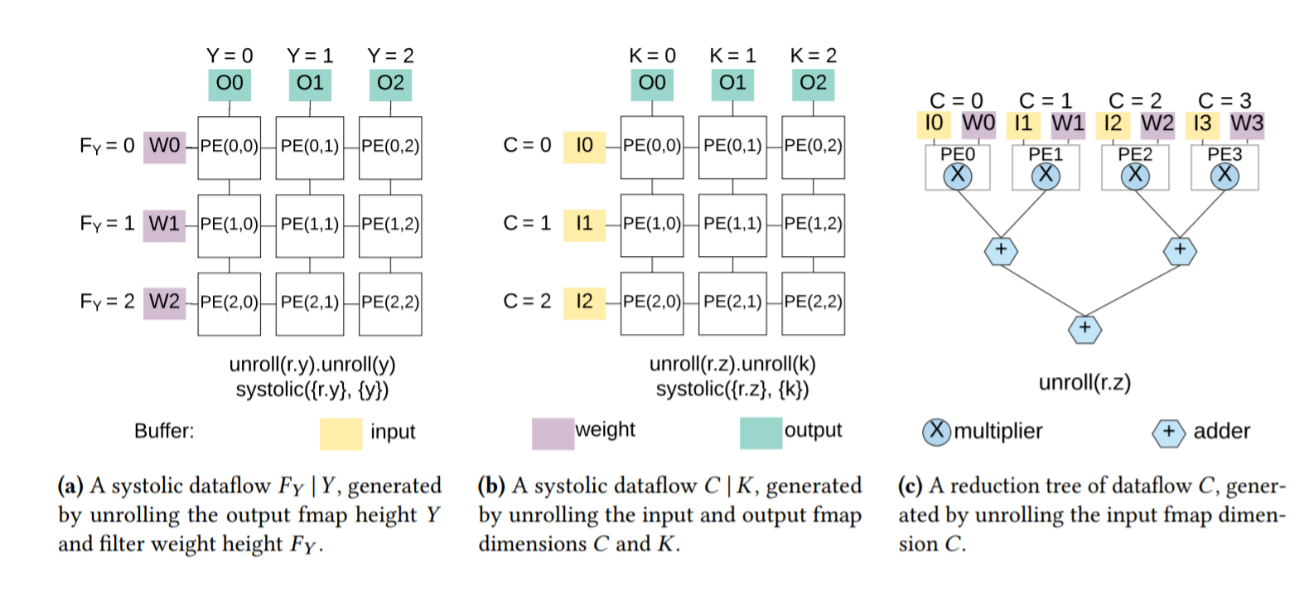
Google TPU所采用的方式。利用fully connected layer,将input channel和output channel分别放到PE列和PE行里,input从上到下进入PE array,output从左到右走出PE array,将其划分成systolic array。
总而言之,Dataflow解决的主要是将哪些数据放在PE上运算及PE运算哪些数据的问题。在本报告中,我实现了三种数据流传输方式,分别选择不同的循环节,将之放入PE进行并行操作。这三种分别为:$X|Y$,$F_Y|Y$与$C|K$。具体操作非常类似,我们以$X|Y$为例,实际上就是将图中的for x = 0 until X与for y = 0 until Y两个语句所表示的循环放入PE进行并行执行。因此实际上循环变为for x = 0 until X / PE.size_X与for y = 0 until Y / PE.size_Y。
/* * the original operation: * O[b][oc][ox][oy] = I[b][ic][ix][iy] * W[oc][ic][wx][wy]; * 3 data flow modes in total */
classpara { public: int size_x; int size_y; int channel_in; int channel_out; int conv_size_x; int conv_size_y; int batch_size; para(int s_x, int s_y, int c_in, int c_out, int c_s_x, int c_s_y, int b_s) { size_x = s_x; size_y = s_y; channel_in = c_in; channel_out = c_out; conv_size_x = c_s_x; conv_size_y = c_s_y; batch_size = b_s; } /*-----------construction function-----------*/ };
classPE { public: int size_x; int size_y; int SIZE; PE(int s_x, int s_y) { size_x = s_x; size_y = s_y; SIZE = size_x * size_y; } /*-----------construction function-----------*/ };
classresult { public: int memory_read_cycle; int memory_write_cycle; int GLB_read_cycle; int GLB_write_cycle; int reg_read_cycle; int reg_write_cycle; int scatter_cycle; int broadcast_cycle; int mac_cycle; int total_cycle; /*-----------cycle numbers of all parameters-----------*/ double memory_read_energy; double memory_write_energy; double GLB_read_energy; double GLB_write_energy; double reg_read_energy; double reg_write_energy; double scatter_energy; double broadcast_energy; double mac_energy; double total_energy; /*-----------energy cost of all parameters-----------*/
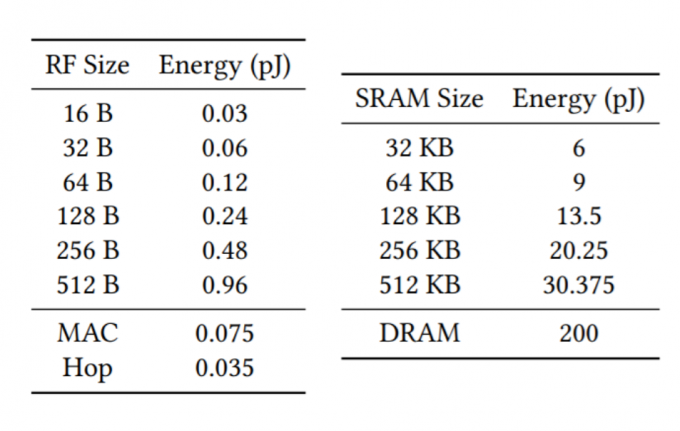
int M_read_cycle = 1; int M_write_cycle = 1; int G_read_cycle = 1; int G_write_cycle = 1; int R_read_cycle = 1; int R_write_cycle = 1; int S_cycle = 1; int B_cycle = 1; int M_cycle = 1; /*-----------initial cycle numbers of all parameters-----------*/ double M_read_energy = SRAM_energy[SRAM_SIZE]; double M_write_energy = SRAM_energy[SRAM_SIZE]; double G_read_energy = SRAM_energy[SRAM_SIZE]; double G_write_energy = SRAM_energy[SRAM_SIZE]; double R_read_energy = RF_energy[RF_SIZE]; double R_write_energy = RF_energy[RF_SIZE]; double S_energy = 200; double B_energy = 0.035; double M_energy = 0.075; /*-----------initial energy cost of all parameters-----------*/ re.memory_read_cycle += M_read_cycle * pa.batch_size * pa.channel_in * (pa.size_x + pa.conv_size_x - 1) * (pa.size_y + pa.conv_size_y - 1); /*-----------read data to buffer-----------*/ re.memory_read_cycle += M_read_cycle * pa.conv_size_x * pa.conv_size_y * pa.channel_in * pa.channel_out; /*-----------read convolution kernel to buffer-----------*/ re.memory_read_cycle += M_read_cycle * pa.batch_size * pa.channel_out * pa.size_x * pa.size_y; /*-----------read data to buffer-----------*/ re.memory_read_energy += M_read_energy * pa.batch_size * pa.channel_in * (pa.size_x + pa.conv_size_x - 1) * (pa.size_y + pa.conv_size_y - 1); /*-----------read data to buffer-----------*/ re.memory_read_energy += M_read_energy * pa.conv_size_x * pa.conv_size_y * pa.channel_in * pa.channel_out; /*-----------read convolution kernel tobuffer-----------*/ re.memory_read_energy += M_read_energy * pa.batch_size * pa.channel_out * pa.size_x * pa.size_y; /*-----------read data to buffer-----------*/
if (data_flow == 0) { for (int b = 0; b < pa.batch_size; b++) for (int oc = 0; oc < pa.channel_out; oc++) for (int ox = 0; ox < ceil((double)pa.size_x / pe.size_x); ++ox) for (int oy = 0; oy < ceil((double) pa.size_y / pe.size_y); ++oy)
/*-----------parallel for ox and oy-----------*/ { re.GLB_read_cycle += G_read_cycle * pe.SIZE; /*-----------read partial sum from GLB-----------*/ re.scatter_cycle += S_cycle; /*-----------assuming scatter is parallel-----------*/ re.reg_write_cycle += R_write_cycle; /*-----------write partial sum to register file-----------*/
re.GLB_read_energy += G_read_energy * pe.SIZE; /*-----------read partial sum from GLB-----------*/ re.scatter_energy += S_energy * pe.SIZE; /*-----------assuming scatter is parallel-----------*/ re.reg_write_energy += R_write_energy * pe.SIZE; /*-----------write partial sum to register file-----------*/
/*-----------the following are in register file-----------*/ for (int ic = 0; ic < pa.channel_in; ++ic) for (int wx = 0; wx < pa.conv_size_x; ++wx) for (int wy = 0; wy < pa.conv_size_y; ++wy) { re.GLB_read_cycle += G_read_cycle; /*-----------read from weight-----------*/ re.broadcast_cycle += B_cycle; /*-----------broadcast, only once-----------*/ re.GLB_read_cycle += G_read_cycle * pe.SIZE; /*-----------read from input-----------*/ re.scatter_cycle += S_cycle; /*-----------read from scatter-----------*/ re.reg_write_cycle += R_write_cycle * 2; /*-----------write input and weight, so 2 times in total-----------*/ re.reg_read_cycle += R_read_cycle * 3; /*-----------read input, output and weight-----------*/ re.mac_cycle += M_cycle; /*-----------multiple and add operation-----------*/ re.reg_write_cycle += R_write_cycle; /*-----------write output back-----------*/
re.GLB_read_energy += G_read_energy; /*-----------read from weight-----------*/ re.broadcast_energy += B_energy * pe.SIZE; /*-----------broadcast, only once-----------*/ re.GLB_read_energy += G_read_energy * pe.SIZE; /*-----------read from input-----------*/ re.scatter_energy += S_energy * pe.SIZE; /*-----------read from scatter-----------*/ re.reg_write_energy += R_write_energy * 2 * pe.SIZE; /*-----------write input and weight, so 2 times in total-----------*/ re.reg_read_energy += R_read_energy * 3 * pe.SIZE; /*-----------read input, output and weight-----------*/ re.mac_energy += M_energy * pe.SIZE; /*-----------multiple and add operation-----------*/ re.reg_write_energy += R_write_energy * pe.SIZE; /*-----------write output back-----------*/ } re.reg_read_cycle += R_read_cycle; /*-----------read from register file and write to buffer-----------*/ re.GLB_write_cycle += G_write_cycle * pe.SIZE; /*-----------write output to buffer-----------*/ re.reg_read_energy += R_read_energy * pe.SIZE; /*-----------read from register file and write to buffer-----------*/ re.GLB_write_energy += G_write_energy * pe.SIZE; /*-----------write output to buffer-----------*/ } re.GLB_read_cycle += G_read_cycle * pa.batch_size * pa.size_x * pa.size_y * pa.channel_out; re.memory_write_cycle += M_write_cycle * pa.batch_size * pa.size_x * pa.size_y * pa.channel_out; /*-----------finally read from GLB and write to memory-----------*/ re.GLB_read_energy += G_read_energy * pa.batch_size * pa.size_x * pa.size_y * pa.channel_out; re.memory_write_energy += M_write_energy * pa.batch_size * pa.size_x * pa.size_y * pa.channel_out; /*-----------finally read from GLB and write to memory-----------*/ } elseif (data_flow == 1) { for (int b = 0; b < pa.batch_size; ++b) for (int oc = 0; oc < pa.channel_out; ++oc) for (int ic = 0; ic < pa.channel_in; ++ic) for (int oy = 0; oy < ceil((double)pa.size_y / pe.size_x); ++oy) for (int wy = 0; wy < ceil((double)pa.conv_size_y / pe.size_y); ++wy) /*-----------parallel for oy and wy-----------*/ for (int ox = 0; ox < pa.size_x; ++ox) for (int wx = 0; wx < pa.conv_size_x; ++wx) { int tmp_x = min(pe.size_x, pa.size_y - oy * pe.size_x); int tmp_y = min(pe.size_y, pa.conv_size_y - wy * pe.size_y); re.GLB_read_cycle += G_read_cycle * (tmp_x + tmp_y - 1); /*-----------GLB read from input-----------*/ re.GLB_read_cycle += G_read_cycle * tmp_y; /*-----------GLB read from weight-----------*/ re.GLB_read_cycle += G_read_cycle * tmp_x; /*-----------GLB read from output-----------*/ re.scatter_cycle += S_cycle * 3; /*-----------the same to mode 0-----------*/ re.reg_write_cycle += R_write_cycle * 3; /*-----------write input, output, weight for 3 times-----------*/ re.mac_cycle += M_cycle; re.reg_read_cycle += R_read_cycle * 3; /*-----------read input, output, weight for 3 times-----------*/ re.reg_write_cycle += R_write_cycle; re.reg_read_cycle += R_read_cycle; re.GLB_write_cycle += G_write_cycle; /*-----------write output to buffer-----------*/